Redis Hash(Hash) 复习
- 陈大剩
- 2022-09-03 23:34:21
- 2207
介绍
哈希相当于一个二维数组,内部是无序字典。
哈希也是是一个 string 类型的 field(字段) 和 value(值) 的映射表,所以哈希特别适合用于存储对象。
应用场景
Hash也可以同于对象存储,比如存储用户信息,与字符串不一样的是,字符串是需要将对象进行序列化(比如json序列化)之后才能保存,而Hash则可以讲用户对象的每个字段单独存储,这样就能节省序列化和反序列的时间。如下:
此外还可以保存用户的购买记录,比如key为用户id ,field为商品id,value为商品数量。同样还可以用于购物车数据的存储,比如key为用户id,field为商品id,value为购买数量等等。
数据结构
哈希是数组 + 链表二维结构。第一维 hash 的数组位置碰撞时,就会将碰撞的元素使用链表串接起来。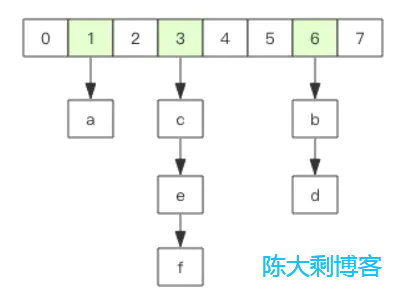
新增(HSET、HMSET)
HSET(推荐)
# HSET key field value [field value ...]
# key 名称 field 第二维数组索引
# 如果哈希表不存在,则创建,存在即覆盖
# 新建字段,设置成功,返回 1 。 存在且旧值已被覆盖,返回 0
> HSET myhash 1 zhangsan 2 lisi 3 wangwu
(integer) 3
不存在时创建(HSETNX)
# 成功,返回 1 。 字段存在,返回 0
# HSETNX key field value
> HSETNX myhash2 1 zhansi
(integer) 1
HSETNX 只能创建单个key-value
HMSET(4.0后已遗弃)
# HMSET key field value [field value ...]
# key 名称 field 第二维数组索引 vakue值
# 如果哈希表不存在,则创建,存在即覆盖
# 执行成功,返回 OK 。
> HMSET myhash1 1 zhangsan 2 lisi 3 wangwu
OK
注意:HMSET无法覆盖旧值,当旧值存在会执行失败
根据Redis 4.0.0,HMSET被视为已弃用。请在新代码中使用HSET。
查询
查看单值 (HGET)
# 获取指定的值
# HGET key field
# 返回给定字段的值。不存在时,返回 nil
> HGET myhash 1
"zhangsan2"
获取给定字段多值(HMGET)
# 返回给定字段值,不存在返回nil
# HMGET key field [field ...]
> HMGET myhash 1 2 3 4
1) "zhangsan2"
2) "lisi"
3) "wangwu1"
4) (nil)
获取所有的字段和值(HGETALL)
# 获取所有的字段和值
# 返回字段及字段值。不存在,返回空列表
# HGETALL key
> HGETALL myhash
1) "1"
2) "zhangsan2"
3) "2"
4) "lisi"
5) "3"
6) "wangwu1"
获取所有的Key(HKEYS)
# 获取所有的字段和值
# 返回域(field)列表。不存在,返回空列表
# HKEYS key
> HKEYS myhash
1) "1"
2) "2"
3) "3"
获取所有的值(HVALS)
# 所有值的列表。 不存在时,返回空列表。
# HVALS key
> HVALS myhash1
1) "zhangsan"
2) "lisi"
3) "wangwu"
统计字段数量(HLEN)
# 返回字段的数量。不存在时,返回 0
# HLEN key
> HLEN myhash1
(integer) 3
其他操作
判断字段是否存在(HEXISTS)
# 存在,返回 1 ,不存在,返回 0
# HEXISTS key field
> HEXISTS myhash 1
(integer) 1
HEXISTS 可以判断
field也可以判断key
自增给定增量(HINCRBY)
# increment增量
# 返回当前字段的值
# HINCRBY key field increment
> hset myhash1 5 5
(integer) 1
> HINCRBY myhash1 5 2
(integer) 7
increment增量可以为负数
自增给定浮点增量(HINCRBYFLOAT)
# increment增量
# 返回当前字段的值
# HINCRBYFLOAT key field increment
> HINCRBYFLOAT myhash1 5 3.5
"10.5"
increment浮点增量可以为负数
迭代(HSCAN)
HSCAN 和 SCAN 类似,HSCAN 针对于hash中的field值,而SCAN针对于redis中所有的key值;
HSCAN key cursor [MATCH pattern] [COUNT count]
MATCH 正则匹配模式
COUNT limit 遍历的条数
重点注意:HSCAN 命令是一个迭代器,是一个迭代器,是一个迭代器!
因为是迭代器,所以每次被调用都需要使用上一次这个调用返回的游标作为该次调用的游标参数,以此来延续之前的迭代过程, 当SCAN命令的游标参数被设置为 0 时, 服务器将开始一次新的迭代, 而当服务器向用户返回值为 0 的游标时, 表示迭代已结束。
讲人话就是 HSCAN 命令返回不是全部元素,需要跟着游标多次迭代才能得到所有的结果。
Redis 6.0 以上版本中 SCAN COUNT参数需要多次迭代遍历,而HSCAN COUNT 不需要多次迭代遍历,只需要设置迭代次数则可以全部迭代
SCAN COUNT 需要如下遍历
遍历结果如:
- 第一次遍历时,cursor值为0
- 将返回结果中第一个整数值作为下一次遍历的cursor
- 一直遍历到返回的cursor的值为0时结束。
SCAN与HSCAN对比
利用Php插入10000条数据
require_once __DIR__ . '/../vendor/autoload.php';
$client = new Predis\Client([
'scheme' => 'tcp',
'host' => '127.0.0.1',
'port' => 6379,
]);
for ($i = 1; $i <= 10000; $i++) {
$client->hset('hash2','key:'.$i,$i);
$client->set('key:'.$i,$i);
}
HSCAN 查询
> HSCAN hash2 0 MATCH "key:99*" count 10000
1) "0"
2) 1) "key:9956"
2) "9956"
3) "key:9998"
4) "9998"
5) "key:9905"
....
221) "key:9962"
222) "9962"
SCAN 查询
> SCAN 0 match "key:99*" count 10000
1) "6655"
2) 1) "key:9956"
2) "key:9998"
3) "key:9905"
....
109) "key:994"
110) "key:9915"
> SCAN 6655 match "key:99*" count 10000
1) "0"
2) 1) "key:9962"
总结
HSCAN 和 SCAN 很大程度上是弥补 KEYS * 的不足;
在生产环境建议少使用
SCAN和KEYS *等命令,一旦数据量大可能会导致宕机或者影响线上环境Redis插入和读写
如果观察到 Redis 的内存大起大落,这极有可能是因为大 key 导致的,需要定位出具体是那个 key,进一步定位出具体的业务来源,然后再改进相关业务代码设计。
普通查大key流程:
SCAN扫码每一个keyTYPE获取字段类型- 用
SIZE或者LEN得到他的大小
Redis 其实在redis-cli 提供了这个功能
redis-cli -h 127.0.0.1 -p 6379 --bigkeys
如果担心指令会大幅提升ops线上报警,可增加一个修满参数,但是查询时间会变长(休眠0.1s)
redis-cli -h 127.0.0.1 -p 6379 —bigkeys -i 0.1


:序言")


:抓取微信ID并发送好友申请")


:序言")
:备考总结")

:学习总结")




